WDIS AI-ML Series: Module 2 Lesson 1: Objective function - AI is nothing but an optimization problem
Written by
Vinay Roy
Published on
27th Mar 2024
Okay from Module 1, we understand a lot of concepts already. Here is a summary.
So now we can get started and start thinking about the end-to-end process map of implementing a machine learning model. To do that, we will have to understand the most important aspect of a Machine learning Model - The objective function. It's the compass that guides algorithms to learn, improve, and ultimately deliver results that matter. But what is it, really? And why is it so central to everything we do in data science?
Let’s begin with a simple story.
2.1.1. What is an objective function?
Imagine you want to teach algebra to your 10-year-old. So that is your objective - To teach your 10-year-old Algebra. You started teaching. A few months have gone by, now how do you know that the kid is on the right track?
A conventional way is to measure the progress through a scoring method. Each problem she solves correctly earns her some points, and each mistake takes away some points. The objective function here then is the total score she gets on the test. It helps you know how well she is learning algebra. So, if she gets a high score, it means she solved most of the problems correctly and understood the algebra concepts well. But if she gets a low score, it tells you that she might need some more practice and help with algebra. In short, the objective function, in this case, is a measure of how much she has learned and how well she is doing in algebra!
Just like your daughter needs feedback to improve her algebra, machines need feedback to improve at tasks they are trained for — whether it's recognizing cats in images, translating text, or forecasting weather.
Defn: In machine learning, an objective function is a mathematical expression that measures how well a model is performing at a specific task. It acts like a thermometer, telling us whether we're getting warmer (closer to the right answer) or colder (further off).
We will look at tons of objective functions in the next few modules.
We all have read some objective functions in our lives even though we may not know them as such or don’t remember them. So let us look at two of them.
2.1.1.1. Accuracy Score: Suppose you want to develop a machine learning algorithm that takes images of animals as input and categorizes them as Cat or Dog. How would you evaluate whether the algorithm is performing well? You can see how many Cat images are categorized as ‘Cat’ by the algorithm and how many Dog images are classified as ‘Dog’. This is called the ‘Accuracy Score’.
If the model labels 90 out of 100 images correctly, its accuracy is 90%. The higher the accuracy score the better the algorithm is said to be performing. Later we will discuss why Accuracy is not a sufficient measure for such cases but for now this is a good enough start.
2.1.1.2. Mean Square Error (MSE) score: Let us go back to our introductory statistics class. Suppose you have a scatter plot as shown below showing the relationship between study hours and test scores. You want to draw a straight line that best represents this relationship.
So which lines L1, L2, L3 describes the data set the best? You are right. It is the line L2. But how did we know that? Just a visual inspection shows that Line L2 is the best-fitting line. But what does the best fitting line mean? How do we measure it? Let us look at it:
Defn: The best fitting line, also known as the regression line or the line of best fit, is a straight line that represents the relationship between two variables, Say X and Y in the above Fig, in a dataset in such a way that it minimizes the overall distance between the observed data points and the line itself.
Okay, but what does minimizing the overall distance between the observed data points and the line mean? Let us look at the same data set as in Fig above through a different lens
In the fig above, there is an observed data point P1. The best-fitting line should be as close to this point P1 as possible. So if Line L2 is the best fitting line then the distance between P1 and L2 i.e. d1 as shown above should be as small as possible. So our goal is to minimize d1. But if we observe more closely, Line L1 is closer to point P1 than Line L2 is. So does that make Line L1 a better fitting line? Yes, it does, but only for point P1. But remember, our goal was not to fit the line to P1 but to fit the line to all the data points or green dots in the figure above. And that is where the trade-off comes in. Said simply, we can move Line L2 close to P1 and thus minimize d1 but not without increasing the distance d2 from point P2.
So how do we ensure L2 is just at the right distance so that both d1 and d2 get minimized? Not only d1, d2 get minimized but all other points are also at the least possible distance away from the best-fitting line?
This is where we need our objective function. Our goal thus could be to minimize: |d1| + |d2| + |d3| + … + |dn| Where |d1| is the mathematical notation for absolute distance i.e. how far apart the point is from the line without worrying about which direction the point is. It's just the total distance between a point and the line, plain and simple. Distance is also called error in statistics books because it shows how much error is there in the observed data point when explained by the best fitting line.
Statisticians found that while the above objective function, Absolute Error, is a good approximation, there is an even better objective function MSE.
Let's compare Absolute Error (AE), Least Squares Error (LSE), and Mean Squared Error (MSE), which are commonly used in regression analysis to evaluate the performance of predictive models:
2.1.1.2.a. Absolute Error (AE): Absolute error measures the absolute difference between the predicted values and the actual values. It is calculated as the sum of the absolute differences between each predicted value and its corresponding actual value.
actual₁, actual₂, ..., actualₙ are the real values from your data
predicted₁, predicted₂, ..., predictedₙ are the model’s guesses
The vertical bars | | mean "just the distance between two numbers" — we don’t care if the guess is too high or too low
AE is robust to outliers because it does not square the errors, but it can be less sensitive to differences between predictions for small errors.
2.1.1.2.b. Least Squares Error (LSE): LSE, also known as the sum of squared errors or the sum of squared residuals, measures the squared difference between the predicted values and the actual values. It is calculated as the sum of the squared differences between each predicted value and its corresponding actual value.
LSE penalizes large errors more heavily than small errors, making it less sensitive to outliers. It is commonly used in ordinary least squares (OLS) regression.
2.1.1.2.c. Mean Squared Error (MSE): MSE is similar to LSE but divides the sum of squared errors by the number of observations, resulting in the average squared error. It is calculated as the mean of the squared differences between each predicted value and its corresponding actual value.
MSE = [(actual₁ - predicted₁)² + (actual₂ - predicted₂)² + ... + (actualₙ - predictedₙ)²] ÷ total number of predictions
MSE provides a measure of the average magnitude of errors in the predictions, making it easier to compare models with different numbers of observations.
Salient Differences between AE, LSE, and MSE:
As we navigate the rest of the course, we will realize that creating an objective function is critical to building the right machine-learning model. However, a harsh truth is that many product and data scientist teams struggle to choose the right objective function because of two reasons:
Trade-offs and right priorities: For one problem statement, there could be many objective functions with a trade-off between them. For example, in the above example of classifying Dog and Cat images, we used the Accuracy score and it served our purpose. But later in the modules, we will see some other objective functions for classification models such as Accuracy vs Precision vs Recall vs. Specificity. Don't worry, if you do not know these metrics, we will talk about these metrics in the later modules but for now, it is enough to realize that data scientists do face tough decisions of choosing the right objective function among a myriad of options.In the other example, we also saw a best-fitting line can have multiple objective functions that we can use - Absolute Error (AE), Least Squares Error (LSE), Mean Squared Error (MSE). Which one to choose depends upon many factors and intimacy with the data set and the problem statement.
Finding connect between the Business Objective and the Machine Learning Objective function: Data scientists love optimizing machine learning metrics. But the truth is companies don't care about Machine learning objectives. They care about business objectives. The only reason they should care about a machine learning objective function is that by moving accuracy from 90% to 92% helps achieve the business objective. This is where the biggest disconnect between data science and the business team is often seen. They are two teams with their respective objective function and without a connecting layer of how one relates to the other. 💡 Ideally, the machine learning objective function should have a direct or indirect effect on the business metric and both business teams should collaborate as equal partners to make sure that happens
Unclear Goals: Sometimes, the goals of the project or analysis may not be well-defined or may be ambiguous. Without clear objectives, it can be difficult to determine which objective function aligns best with the desired outcomes.
Complexity of the Problem: In many cases, the problem being addressed by the data scientist is complex and multifaceted. Understanding the nuances of the problem and how different objective functions may impact the results can be challenging.
2.1.2. Custom Objective Functions: Where Data Science Meets Business Reality
In many real-world machine learning projects, standard objective functions like accuracy, mean squared error, or F1 score are not enough. While these are mathematically convenient, they don't always reflect what the business actually cares about.
That’s where custom objective functions come in.
Why Build a Custom Objective Function? Because machine learning is not just a math problem — it’s a business problem.
Businesses don’t care whether your model's mean squared error dropped from 0.14 to 0.12 unless it leads to real-world improvement: more revenue, fewer customer complaints, faster deliveries, or higher satisfaction.
To close this gap, data scientists sometimes design their own objective functions — formulas that optimize exactly what matters to the business.
2.1.2.1. What Does It Take to Build a Custom Objective Function?
Creating a custom objective function is like designing a target that your machine learning model should aim for. To do this well, you need:
Deep understanding of the business problem: You need to know not just what the model is predicting, but why that prediction matters, and how wrong predictions hurt the business.
Clear, quantifiable impact: The outcome must be measurable. "Make customers happier" is too vague. But "reduce refund rate" or "increase daily active users" is specific and measurable.
Mathematical expression of the goal: If you're using techniques like gradient descent, the objective function must be differentiable — it needs to be smooth enough for the model to learn from it.
2.1.2.2. Examples of Custom Objective Functions in the Real World
Here are several examples — across industries — to show what this looks like in practice:
2.1.2.2.a. E-commerce: Maximize Revenue per Email Sent
Business Goal: Increase revenue from promotional campaigns Custom Objective: Instead of just maximizing click-through rate (CTR), the model should optimize:
This rewards campaigns that drive high spending with fewer emails, not just campaigns that get lots of clicks.
2.1.2.2.b. Delivery & Logistics: Minimize Late Deliveries with Priority Weighting
Business Goal: Deliver on time, especially for VIP customers Custom Objective: Penalize late deliveries more if the customer is high priority:
This ensures the model gives extra attention to high-value customers and optimizes for what the business truly values: timeliness for important clients.
2.1.2.2.c. Finance: Maximize True Positives While Controlling False Alarms
Business Goal: Detect fraud, but don't annoy honest customers Custom Objective:
Where λ (Lambda) is a penalty factor for flagging legitimate transactions. This balances risk reduction with customer experience.
2.1.2.2.d. Healthcare: Early Disease Detection With Severity Adjustment
Business Goal: Catch serious diseases as early as possible Custom Objective:
This way, predicting early signs of life-threatening conditions is valued much more than catching mild cases. It aligns the model’s incentives with medical urgency.
Business Goal: Help students improve the most, not just score high Custom Objective:
The model is rewarded for helping users learn and improve, not just for working with already high-performing students.
2.1.2.2.f. Subscription Businesses: Maximize Retention Value
Business Goal: Predict which users to retain based on lifetime value (LTV) Custom Objective:
This way, the model prioritizes retaining customers who are likely to bring more revenue.
2.1.2.3. Challenges to Watch For when designing the Custom Objective Function
Designing one requires cross-functional collaboration (business + data science)
Can be harder to train and debug
Needs careful testing and validation to ensure the function is guiding the model correctly
2.1.3. Loss Function vs. Cost Function vs. Objective Function
When we train machine learning models, we often talk about the accuracy or error of predictions. But behind the scenes, every model is guided by one or more mathematical tools that measure how wrong it is — and help it learn from those mistakes.
These tools go by names like loss function, cost function, and objective function.
For beginners, these terms can feel confusing — sometimes they’re used interchangeably, sometimes they’re not. But to truly understand what’s happening under the hood of a model, it’s important to know the differences and how they fit together.
Let’s break it down clearly and intuitively.
The objective function is the heart of a machine learning model. Choose the wrong objective function and you will end up wasting a massive amount of technology effort and causing a disappointment about what machine learning can do for the business. However, choosing the right objective function is not just a technical challenge but a cultural challenge that connects business imperatives, data quality, autonomy of the data science team, and an enviable collaboration.
In the next set of lessons, we will talk about the whole end to end process map of taking a problem statement from building a business objective function to choosing the right machine learning objective function to picking the right machine learning model to deploying the model into production. It will get exciting, hang on and keep reading. The best is yet to come.
As a photographer, it’s important to get the visuals right while establishing your online presence. Having a unique and professional portfolio will make you stand out to potential clients. The only problem? Most website builders out there offer cookie-cutter options — making lots of portfolios look the same.
That’s where a platform like Webflow comes to play. With Webflow you can either design and build a website from the ground up (without writing code) or start with a template that you can customize every aspect of. From unique animations and interactions to web app-like features, you have the opportunity to make your photography portfolio site stand out from the rest.
So, we put together a few photography portfolio websites that you can use yourself — whether you want to keep them the way they are or completely customize them to your liking.
12 photography portfolio websites to showcase your work
Here are 12 photography portfolio templates you can use with Webflow to create your own personal platform for showing off your work.
WDIS AI-ML Series: Module 2 Lesson 1: Objective function - AI is nothing but an optimization problem
Vinay Roy
27th Mar 2024
Introduction
An objective function in the context of machine learning is a mathematical function that quantifies how well the algorithm is performing at a particular task.
Table of Contents
Key Takeaways
A Framework for Framing ML Problems
Clarify the Business Objective
Frame the ML Problem
Design the ML Pipeline
Define Success Metrics
Plan for Deployment & Beyond
Continually Measure Business Impact
Conclusion
Okay from Module 1, we understand a lot of concepts already. Here is a summary.
So now we can get started and start thinking about the end-to-end process map of implementing a machine learning model. To do that, we will have to understand the most important aspect of a Machine learning Model - The objective function. It's the compass that guides algorithms to learn, improve, and ultimately deliver results that matter. But what is it, really? And why is it so central to everything we do in data science?
Let’s begin with a simple story.
2.1.1. What is an objective function?
Imagine you want to teach algebra to your 10-year-old. So that is your objective - To teach your 10-year-old Algebra. You started teaching. A few months have gone by, now how do you know that the kid is on the right track?
A conventional way is to measure the progress through a scoring method. Each problem she solves correctly earns her some points, and each mistake takes away some points. The objective function here then is the total score she gets on the test. It helps you know how well she is learning algebra. So, if she gets a high score, it means she solved most of the problems correctly and understood the algebra concepts well. But if she gets a low score, it tells you that she might need some more practice and help with algebra. In short, the objective function, in this case, is a measure of how much she has learned and how well she is doing in algebra!
Just like your daughter needs feedback to improve her algebra, machines need feedback to improve at tasks they are trained for — whether it's recognizing cats in images, translating text, or forecasting weather.
Defn: In machine learning, an objective function is a mathematical expression that measures how well a model is performing at a specific task. It acts like a thermometer, telling us whether we're getting warmer (closer to the right answer) or colder (further off).
We will look at tons of objective functions in the next few modules.
We all have read some objective functions in our lives even though we may not know them as such or don’t remember them. So let us look at two of them.
2.1.1.1. Accuracy Score: Suppose you want to develop a machine learning algorithm that takes images of animals as input and categorizes them as Cat or Dog. How would you evaluate whether the algorithm is performing well? You can see how many Cat images are categorized as ‘Cat’ by the algorithm and how many Dog images are classified as ‘Dog’. This is called the ‘Accuracy Score’.
If the model labels 90 out of 100 images correctly, its accuracy is 90%. The higher the accuracy score the better the algorithm is said to be performing. Later we will discuss why Accuracy is not a sufficient measure for such cases but for now this is a good enough start.
2.1.1.2. Mean Square Error (MSE) score: Let us go back to our introductory statistics class. Suppose you have a scatter plot as shown below showing the relationship between study hours and test scores. You want to draw a straight line that best represents this relationship.
So which lines L1, L2, L3 describes the data set the best? You are right. It is the line L2. But how did we know that? Just a visual inspection shows that Line L2 is the best-fitting line. But what does the best fitting line mean? How do we measure it? Let us look at it:
Defn: The best fitting line, also known as the regression line or the line of best fit, is a straight line that represents the relationship between two variables, Say X and Y in the above Fig, in a dataset in such a way that it minimizes the overall distance between the observed data points and the line itself.
Okay, but what does minimizing the overall distance between the observed data points and the line mean? Let us look at the same data set as in Fig above through a different lens
In the fig above, there is an observed data point P1. The best-fitting line should be as close to this point P1 as possible. So if Line L2 is the best fitting line then the distance between P1 and L2 i.e. d1 as shown above should be as small as possible. So our goal is to minimize d1. But if we observe more closely, Line L1 is closer to point P1 than Line L2 is. So does that make Line L1 a better fitting line? Yes, it does, but only for point P1. But remember, our goal was not to fit the line to P1 but to fit the line to all the data points or green dots in the figure above. And that is where the trade-off comes in. Said simply, we can move Line L2 close to P1 and thus minimize d1 but not without increasing the distance d2 from point P2.
So how do we ensure L2 is just at the right distance so that both d1 and d2 get minimized? Not only d1, d2 get minimized but all other points are also at the least possible distance away from the best-fitting line?
This is where we need our objective function. Our goal thus could be to minimize: |d1| + |d2| + |d3| + … + |dn| Where |d1| is the mathematical notation for absolute distance i.e. how far apart the point is from the line without worrying about which direction the point is. It's just the total distance between a point and the line, plain and simple. Distance is also called error in statistics books because it shows how much error is there in the observed data point when explained by the best fitting line.
Statisticians found that while the above objective function, Absolute Error, is a good approximation, there is an even better objective function MSE.
Let's compare Absolute Error (AE), Least Squares Error (LSE), and Mean Squared Error (MSE), which are commonly used in regression analysis to evaluate the performance of predictive models:
2.1.1.2.a. Absolute Error (AE): Absolute error measures the absolute difference between the predicted values and the actual values. It is calculated as the sum of the absolute differences between each predicted value and its corresponding actual value.
actual₁, actual₂, ..., actualₙ are the real values from your data
predicted₁, predicted₂, ..., predictedₙ are the model’s guesses
The vertical bars | | mean "just the distance between two numbers" — we don’t care if the guess is too high or too low
AE is robust to outliers because it does not square the errors, but it can be less sensitive to differences between predictions for small errors.
2.1.1.2.b. Least Squares Error (LSE): LSE, also known as the sum of squared errors or the sum of squared residuals, measures the squared difference between the predicted values and the actual values. It is calculated as the sum of the squared differences between each predicted value and its corresponding actual value.
LSE penalizes large errors more heavily than small errors, making it less sensitive to outliers. It is commonly used in ordinary least squares (OLS) regression.
2.1.1.2.c. Mean Squared Error (MSE): MSE is similar to LSE but divides the sum of squared errors by the number of observations, resulting in the average squared error. It is calculated as the mean of the squared differences between each predicted value and its corresponding actual value.
MSE = [(actual₁ - predicted₁)² + (actual₂ - predicted₂)² + ... + (actualₙ - predictedₙ)²] ÷ total number of predictions
MSE provides a measure of the average magnitude of errors in the predictions, making it easier to compare models with different numbers of observations.
Salient Differences between AE, LSE, and MSE:
As we navigate the rest of the course, we will realize that creating an objective function is critical to building the right machine-learning model. However, a harsh truth is that many product and data scientist teams struggle to choose the right objective function because of two reasons:
Trade-offs and right priorities: For one problem statement, there could be many objective functions with a trade-off between them. For example, in the above example of classifying Dog and Cat images, we used the Accuracy score and it served our purpose. But later in the modules, we will see some other objective functions for classification models such as Accuracy vs Precision vs Recall vs. Specificity. Don't worry, if you do not know these metrics, we will talk about these metrics in the later modules but for now, it is enough to realize that data scientists do face tough decisions of choosing the right objective function among a myriad of options.In the other example, we also saw a best-fitting line can have multiple objective functions that we can use - Absolute Error (AE), Least Squares Error (LSE), Mean Squared Error (MSE). Which one to choose depends upon many factors and intimacy with the data set and the problem statement.
Finding connect between the Business Objective and the Machine Learning Objective function: Data scientists love optimizing machine learning metrics. But the truth is companies don't care about Machine learning objectives. They care about business objectives. The only reason they should care about a machine learning objective function is that by moving accuracy from 90% to 92% helps achieve the business objective. This is where the biggest disconnect between data science and the business team is often seen. They are two teams with their respective objective function and without a connecting layer of how one relates to the other. 💡 Ideally, the machine learning objective function should have a direct or indirect effect on the business metric and both business teams should collaborate as equal partners to make sure that happens
Unclear Goals: Sometimes, the goals of the project or analysis may not be well-defined or may be ambiguous. Without clear objectives, it can be difficult to determine which objective function aligns best with the desired outcomes.
Complexity of the Problem: In many cases, the problem being addressed by the data scientist is complex and multifaceted. Understanding the nuances of the problem and how different objective functions may impact the results can be challenging.
2.1.2. Custom Objective Functions: Where Data Science Meets Business Reality
In many real-world machine learning projects, standard objective functions like accuracy, mean squared error, or F1 score are not enough. While these are mathematically convenient, they don't always reflect what the business actually cares about.
That’s where custom objective functions come in.
Why Build a Custom Objective Function? Because machine learning is not just a math problem — it’s a business problem.
Businesses don’t care whether your model's mean squared error dropped from 0.14 to 0.12 unless it leads to real-world improvement: more revenue, fewer customer complaints, faster deliveries, or higher satisfaction.
To close this gap, data scientists sometimes design their own objective functions — formulas that optimize exactly what matters to the business.
2.1.2.1. What Does It Take to Build a Custom Objective Function?
Creating a custom objective function is like designing a target that your machine learning model should aim for. To do this well, you need:
Deep understanding of the business problem: You need to know not just what the model is predicting, but why that prediction matters, and how wrong predictions hurt the business.
Clear, quantifiable impact: The outcome must be measurable. "Make customers happier" is too vague. But "reduce refund rate" or "increase daily active users" is specific and measurable.
Mathematical expression of the goal: If you're using techniques like gradient descent, the objective function must be differentiable — it needs to be smooth enough for the model to learn from it.
2.1.2.2. Examples of Custom Objective Functions in the Real World
Here are several examples — across industries — to show what this looks like in practice:
2.1.2.2.a. E-commerce: Maximize Revenue per Email Sent
Business Goal: Increase revenue from promotional campaigns Custom Objective: Instead of just maximizing click-through rate (CTR), the model should optimize:
This rewards campaigns that drive high spending with fewer emails, not just campaigns that get lots of clicks.
2.1.2.2.b. Delivery & Logistics: Minimize Late Deliveries with Priority Weighting
Business Goal: Deliver on time, especially for VIP customers Custom Objective: Penalize late deliveries more if the customer is high priority:
This ensures the model gives extra attention to high-value customers and optimizes for what the business truly values: timeliness for important clients.
2.1.2.2.c. Finance: Maximize True Positives While Controlling False Alarms
Business Goal: Detect fraud, but don't annoy honest customers Custom Objective:
Where λ (Lambda) is a penalty factor for flagging legitimate transactions. This balances risk reduction with customer experience.
2.1.2.2.d. Healthcare: Early Disease Detection With Severity Adjustment
Business Goal: Catch serious diseases as early as possible Custom Objective:
This way, predicting early signs of life-threatening conditions is valued much more than catching mild cases. It aligns the model’s incentives with medical urgency.
Business Goal: Help students improve the most, not just score high Custom Objective:
The model is rewarded for helping users learn and improve, not just for working with already high-performing students.
2.1.2.2.f. Subscription Businesses: Maximize Retention Value
Business Goal: Predict which users to retain based on lifetime value (LTV) Custom Objective:
This way, the model prioritizes retaining customers who are likely to bring more revenue.
2.1.2.3. Challenges to Watch For when designing the Custom Objective Function
Designing one requires cross-functional collaboration (business + data science)
Can be harder to train and debug
Needs careful testing and validation to ensure the function is guiding the model correctly
2.1.3. Loss Function vs. Cost Function vs. Objective Function
When we train machine learning models, we often talk about the accuracy or error of predictions. But behind the scenes, every model is guided by one or more mathematical tools that measure how wrong it is — and help it learn from those mistakes.
These tools go by names like loss function, cost function, and objective function.
For beginners, these terms can feel confusing — sometimes they’re used interchangeably, sometimes they’re not. But to truly understand what’s happening under the hood of a model, it’s important to know the differences and how they fit together.
Let’s break it down clearly and intuitively.
The objective function is the heart of a machine learning model. Choose the wrong objective function and you will end up wasting a massive amount of technology effort and causing a disappointment about what machine learning can do for the business. However, choosing the right objective function is not just a technical challenge but a cultural challenge that connects business imperatives, data quality, autonomy of the data science team, and an enviable collaboration.
In the next set of lessons, we will talk about the whole end to end process map of taking a problem statement from building a business objective function to choosing the right machine learning objective function to picking the right machine learning model to deploying the model into production. It will get exciting, hang on and keep reading. The best is yet to come.
About the author:
Vinay Roy
Fractional AI / ML Strategist | ex-CPO | ex-Nvidia | ex-Apple | UC Berkeley
How do we use this data that exists in the Data warehouse and/or Data Lake to build Machine Learning (ML) models? However, before we build models, we need to gain a deeper understanding of our data.
Not many companies invest enough in data as much as they do in Data Science. Albeit the realization is growing that to be seen as an ‘AI-first’ company, one needs to establish itself as a ‘Data-first’ company. The biggest challenge In this section we will give an overview of what end-to-end data processing looks like from the viewpoint of a data science project:
In this lesson, we will learn to do it the right way and we will also introduce the concept of PRD - Product Requirement Document, a wildly misused or unused tool that is needed to align people on a common mission.








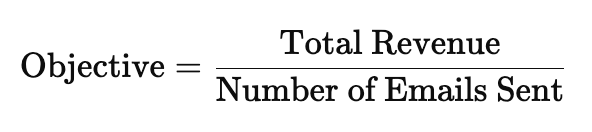







.png)






