
Regression is one of the most foundational problem types in machine learning. It is the family of models used whenever the outcome we care about is a continuous numeric quantity. Regression models power many of the most common predictive systems in business:
In all of these cases, the question is not which category something belongs to, but rather:
What numeric value should we expect?
This is the defining characteristic of regression.

Recall the basic structure of machine learning:
y^=f(x) Where:
In regression, the output belongs to the continuous domain: y∈R
The goal is to learn a function that produces predictions as close as possible to reality.
Suppose we want to predict the sale price of a home.
Inputs might include:
Output:
The model learns:
Price = f(Size,Bedrooms,Location,Age,… )
Once trained, the model can estimate the price of new homes before they sell.
Regression models learn by minimizing prediction error.
The most common objective is the Mean Squared Error. We discussed this WDIS AI-ML Series: Module 2 Lesson 1: Objective function - AI is nothing but an optimization problem:


This objective captures a simple principle:
A good regression model is one that makes predictions close to the true numeric outcomes.

Different regression models differ primarily in how they represent the function f(x).
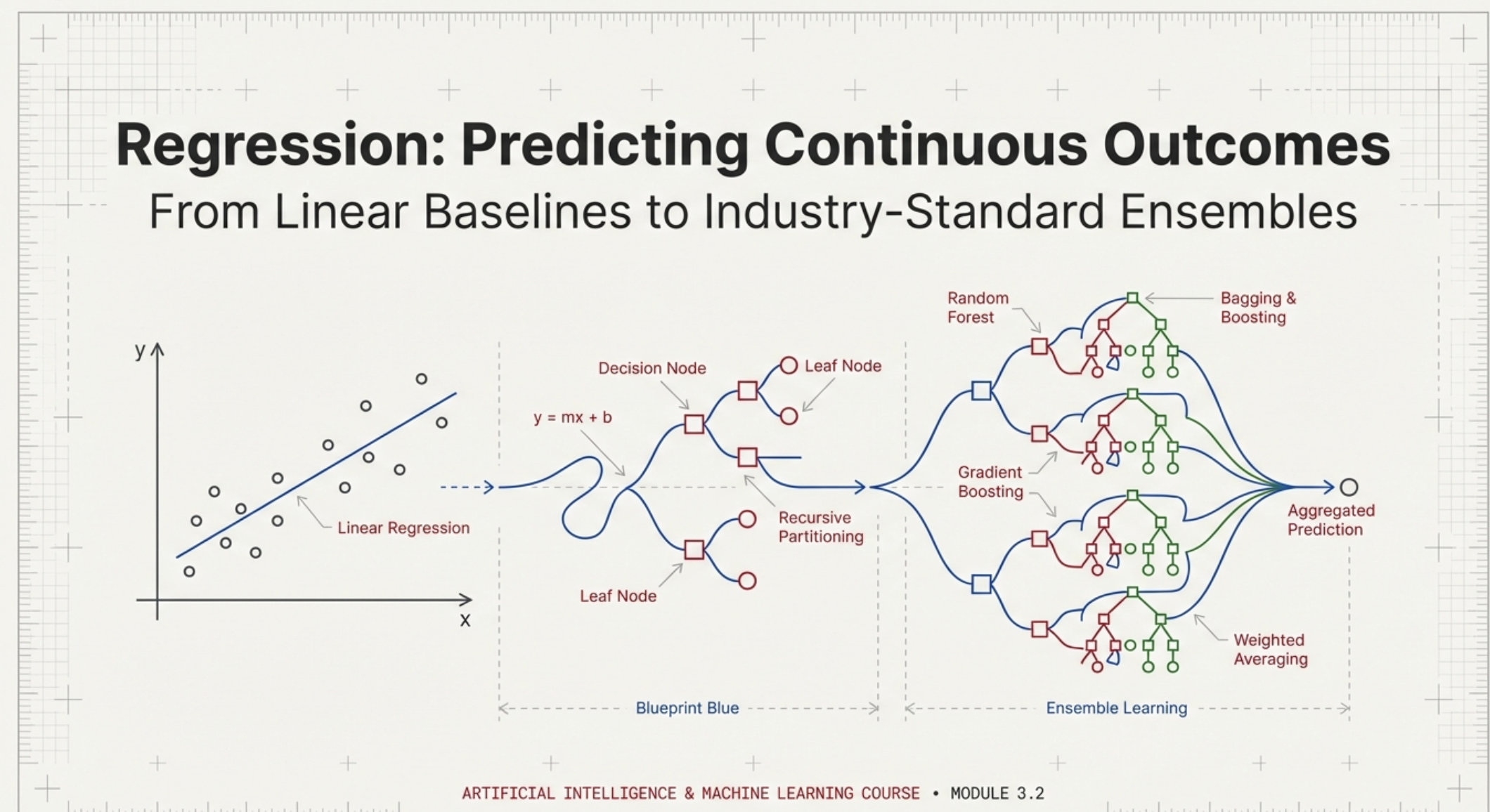
Linear regression is the simplest regression model and remains one of the most widely used tools in applied analytics.
It assumes the relationship between features and outcome can be approximated by a linear combination:
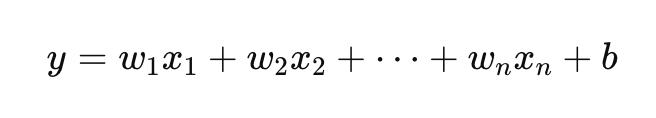
Where:
A linear regression model treats each feature as contributing additively to the final prediction.

For example:
Each coefficient represents the marginal effect of that feature.
A trained model might learn:
Price = 200⋅Size + 15,000⋅Bedrooms+ 50,000⋅NeighborhoodScore
Interpretation:
This interpretability is why linear regression is often preferred in regulated or stakeholder-heavy environments.
Linear regression performs well when:
It is widely used in:
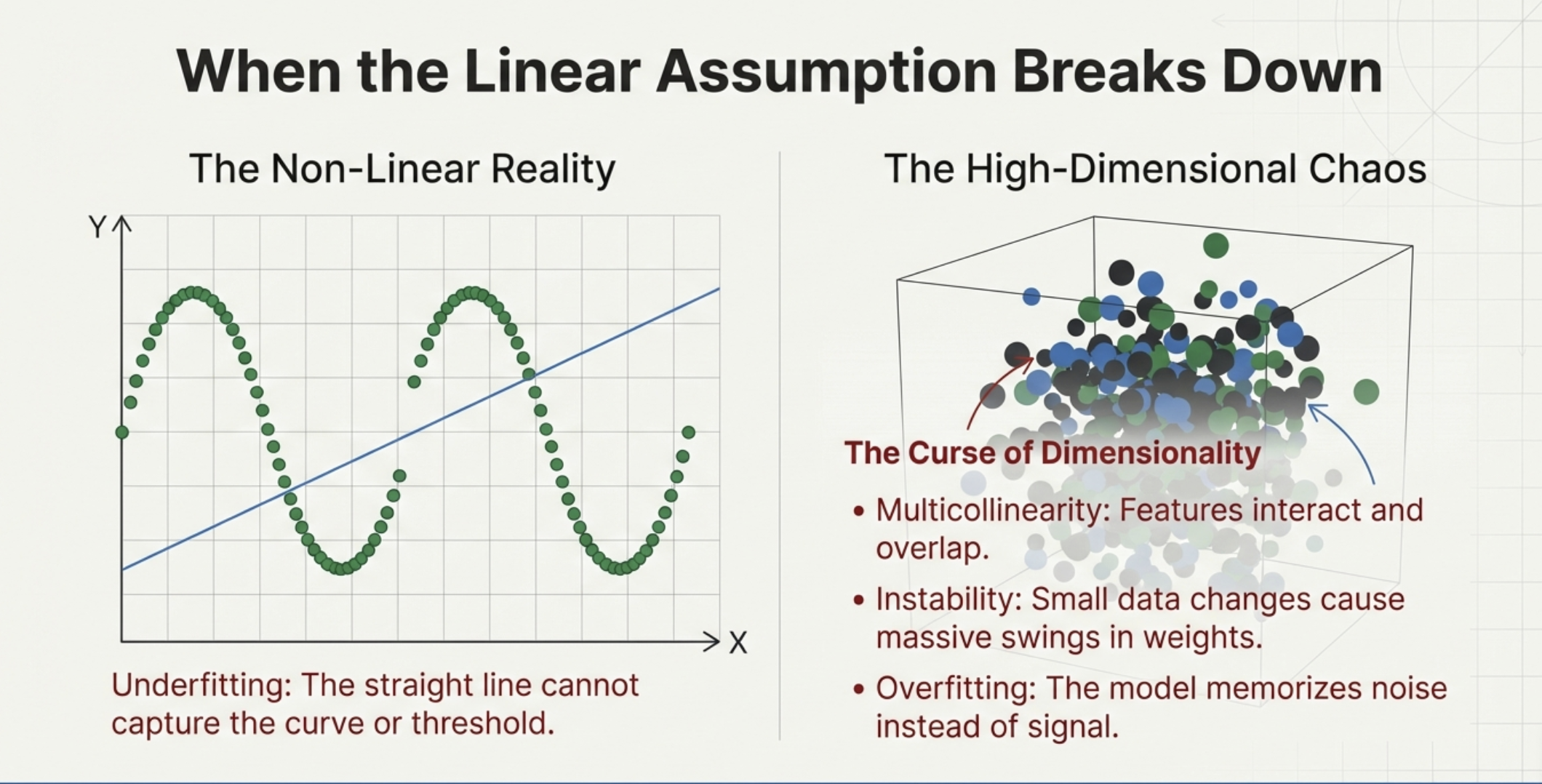
Linear regression struggles when:
Example:
House prices do not rise smoothly. They jump sharply when crossing neighborhood boundaries.
Linear regression cannot naturally represent such discontinuities.
This motivates regularization and nonlinear models.

Modern regression problems often involve high-dimensional feature spaces. For example, predicting customer lifetime value might include:
In such settings, ordinary linear regression tends to overfit. Why? More variables ⇒ More dimension ⇒ More chances of overfitting. We will discuss this in detail when we get to overfitting section.
Regularization solves this by penalizing complexity. So, in short it leans towards a simpler model. How? Let us look at some of the regularization techniques.
Ridge regression modifies the loss function:
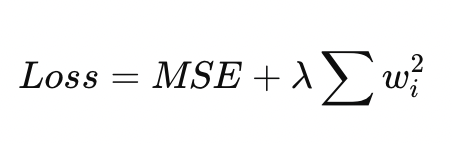
The penalty discourages large coefficients.
When features are correlated (common in business data), linear regression becomes unstable:
Ridge smooths the model and improves generalization.
Forecasting revenue using many correlated predictors:
Ridge regression stabilizes estimates.
Lasso adds a different penalty:

The key difference:
This makes Lasso a feature selection method.
A churn regression model with 500 features:
This is valuable for:
Elastic Net combines Stability and Feature Selection in High-Dimensional Settings by combining Ridge and Lasso.

Most real-world datasets contain many features, many of which are correlated, noisy, or redundant.
In such environments, ordinary linear regression becomes unstable, and even Ridge or Lasso alone may not be sufficient.
Elastic Net was developed as a hybrid approach that combines the strengths of both major regularization methods:
As a result, Elastic Net is often one of the most effective and widely used regression techniques in high-dimensional applied machine learning.
It is often the best practical choice in high-dimensional business regression problems.
To understand Elastic Net, it helps to recall what Ridge and Lasso each do well—and where they struggle.
Ridge regression adds an L2 penalty:

This discourages large coefficients and produces stable models when predictors are correlated.
However, Ridge has one limitation:
So Ridge does not perform feature selection.
The model still includes all predictors, just with smaller weights.
This can reduce interpretability and make deployment harder when hundreds of features remain active.
Lasso regression adds an L1 penalty:

Its key advantage is sparsity:
But Lasso struggles when features are highly correlated.
In business datasets, this is extremely common:
In such cases, Lasso tends to behave unpredictably:
Elastic Net addresses these limitations by combining both penalties:
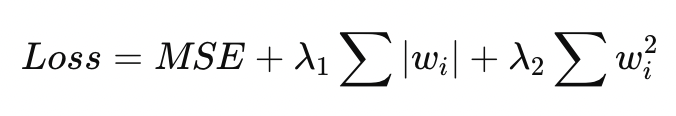
This means Elastic Net encourages:
Instead of choosing between Ridge or Lasso, Elastic Net provides a continuum between them.
Elastic Net has three major advantages that make it especially useful in practice.
Elastic Net can eliminate irrelevant predictors, but unlike pure Lasso, it does so in a more stable way. This is particularly important when features are correlated. Instead of picking one feature and discarding the rest, Elastic Net often keeps groups of related predictors together.
Example:
These features are highly correlated signals of engagement. Elastic Net tends to treat them as a group rather than selecting one arbitrarily.
Elastic Net is especially valuable when:
This is common in real organizational datasets:
Because business data often has:
Elastic Net becomes a highly practical “default” regression model. It often performs better than Ridge or Lasso alone in applied settings.
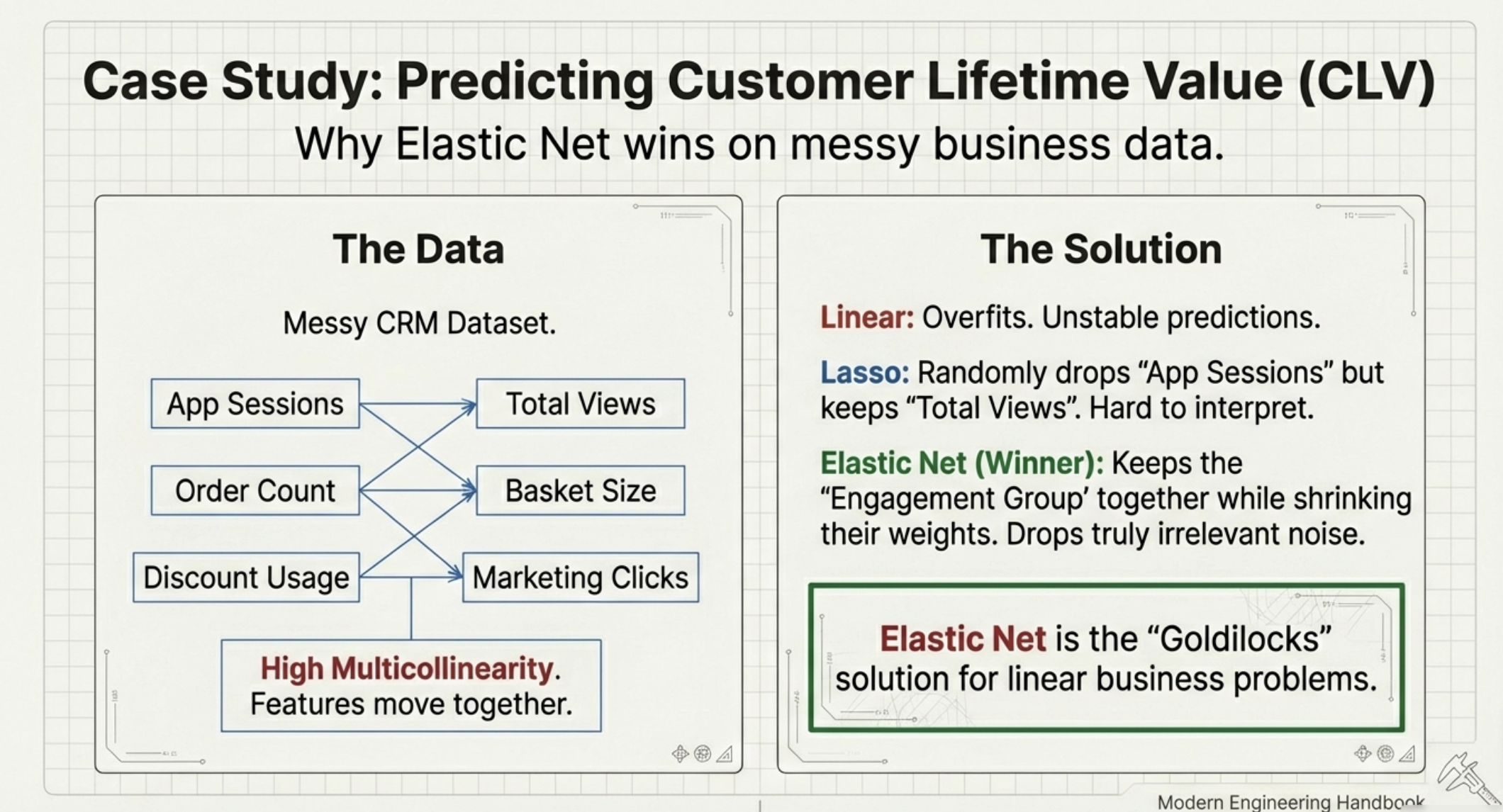
Consider an e-commerce company trying to predict:
CLV=f(CustomerBehavior, Purchases, MarketingExposure, EngagementSignals,…)
The feature set might include:
Many of these features are correlated.
In this setting:
Thus, Elastic Net becomes one of the most reliable models for structured business prediction problems.
Elastic Net is particularly useful when:
It is commonly applied in:
In practice, Elastic Net often sits at an important point in the modeling ladder:
Elastic Net is often the final step in the “linear family” before organizations move to nonlinear ensembles.
Elastic Net is a hybrid regularized regression model that combines:
It is one of the most practical choices for high-dimensional business regression problems because real-world organizational data is rarely clean, independent, or low-dimensional.
Elastic Net provides a balanced approach:
Linear models assume additive relationships.
Decision trees remove this assumption.

A tree learns rules such as:
Trees partition the feature space into regions.
Tree regression naturally captures:
Example: Square footage matters much more in expensive neighborhoods than in cheap ones. Trees represent this interaction automatically.
Single trees are rarely deployed alone because they:
This leads to ensembles.
How to combine multiple models (In this case Trees) together, In comes, Ensemble Learning
When a single model is not strong enough on its own, one of the most powerful ideas in machine learning is to combine many models together to produce a better predictor. This approach is called ensemble learning.
The central intuition is simple: a single decision tree (or model) is often unstable. It may capture patterns in the data, but small changes in the training set can lead to very different trees, and individual trees are prone to overfitting. By building multiple trees and aggregating their outputs, we can reduce these weaknesses and create a model that is more accurate, more robust, and more reliable on unseen data.
In ensemble learning, instead of relying on one tree’s judgment, we rely on the collective intelligence of many trees. Each tree acts as a “weak learner,” making imperfect predictions, but when combined, the ensemble becomes a “strong learner.” There are two primary ways to combine trees or Machine learning Models.
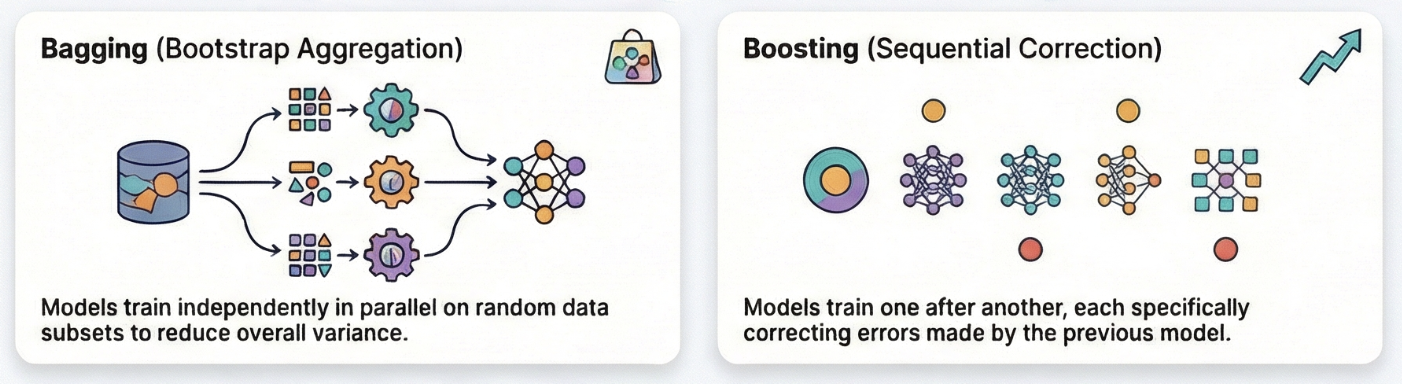
Random Forest builds many trees and averages them.
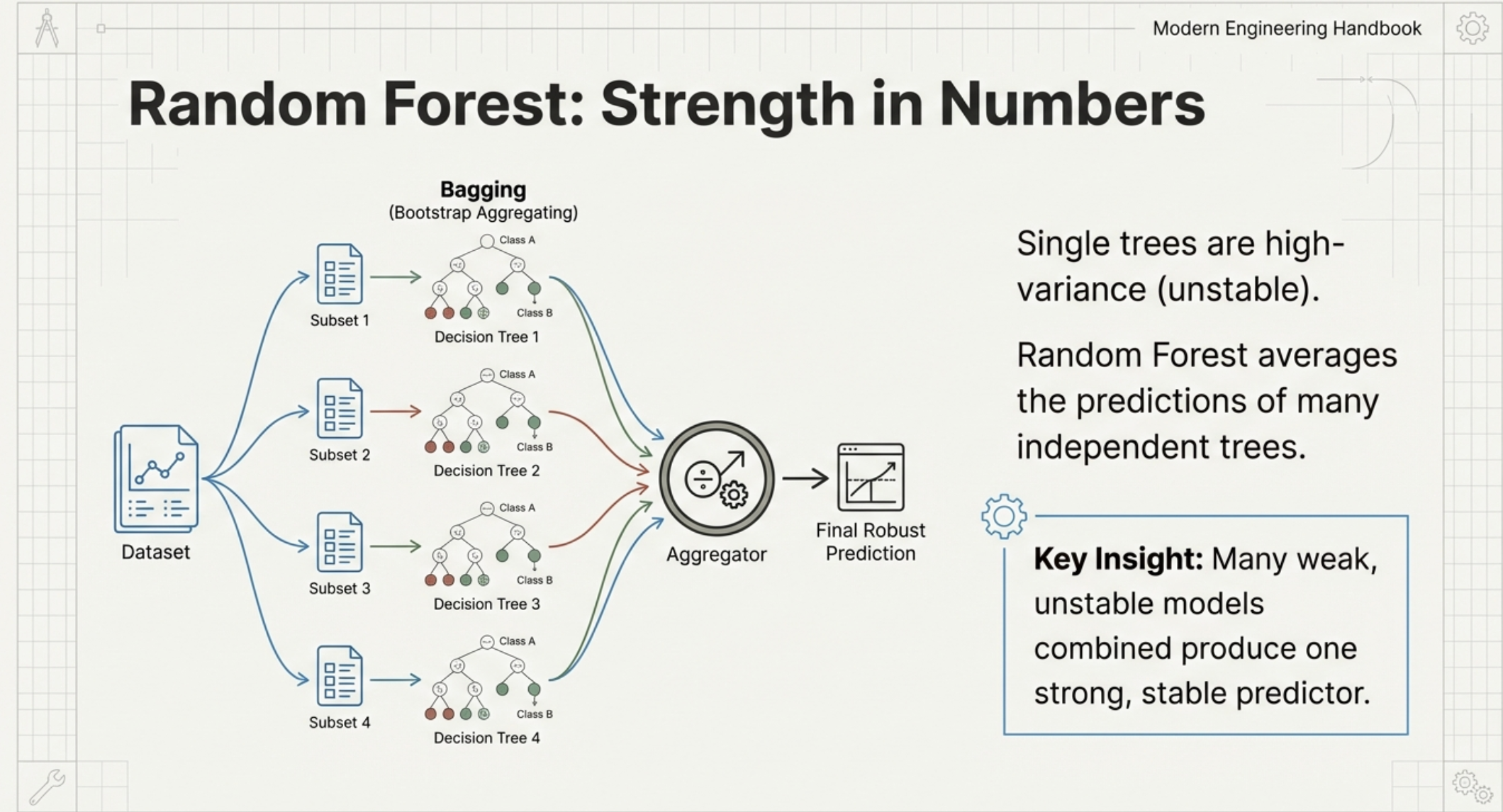
Key idea:
Many weak models combined produce a strong, stable predictor.
Random forests reduce overfitting and improve robustness.
Predicting delivery times with many interacting factors:
Random forests handle these nonlinearities effectively.
Gradient boosting is the most successful regression approach on structured business datasets.
XGBoost is the most widely adopted implementation.

Boosting builds models sequentially:
This is why boosting is often described as:
An iterative process of error correction.
XGBoost is widely used because it:
An e-commerce firm predicts Custome Lifetime Value (CLV) as:
CLV = f(PurchaseHistory, Engagement, Discounts, Demographics,…)
CLV drives decisions such as:
XGBoost is often chosen because:
XGBoost performance depends heavily on tuning:
This is why boosting is powerful but requires careful validation.
Regression is evaluated by error magnitude.
Common metrics: We discuss these in WDIS AI-ML Series: Module 2 Lesson 1: Objective function - AI is nothing but an optimization problem
Absolute Error (AE), Mean Absolute Error (MAE), Root Mean Squared Error (RMSE).
.png)
If large errors are catastrophic (pricing, fraud loss), RMSE matters.
If average error is sufficient (forecasting), MAE may be preferred.
Regression modeling is rarely a one-shot algorithm choice.
Most teams follow a progression:
The goal is not complexity.
The goal is reliable numeric prediction that supports decision-making.
Regression models predict continuous numeric outcomes.
They form a hierarchy:

Regression is foundational because organizations constantly need to estimate quantities before acting.
Regression answers: How much?
Classification answers: Which category?

In the next section, we will study classification models, beginning with logistic regression and moving through decision trees, random forests, gradient boosting, support vector machines, and neural networks.




.webp)